
On this article, I share my experiences on undergoing a paradigm shift from Batch based to RealTime stream based processing over the course of building a realtime data enrichment pipeline which performs join & lookup in real time.
When the volume of data increases to a point that a single DB cant handle it in a cost effective manner, a switch to Hadoop and its ecosystem is imminent. Assuming that the operation which needs to be performed doesn’t need to be Strict A.C.I.D. complaint, the B.A.S.E. model of Hadoop databases like Hive, Impala or even HBase will merrily serve the needs handling TBs of data and crunching through it to give the desired output.
Being horizontally scalable also helps as the cluster can simply be plugged-in with new machines to give direct scaling without changing the code or manually changing the way data is stored in nearly all of the scenarios. You can check out my previous article where i wrote about scaling and parallelism in general.
However, when the same data is arriving in streams (imagine one row at a time) , and needs to be processed at arrival time with minimal latency, both of systems mentioned above will fail.
- The RDBMS SQL server will be brought to a crawl due to the sheer volume or velocity of the incoming messages. whereas
- The above mentioned BigData databases simply aren’t nimble enough to have a turn around time quicker for serving realtime needs.
Looking at the scenario, it dawned on me that I need to start looking towards the other end of the spectrum.
Idiosyncrasies of Real-Time Processing
I will give a brief gist here before going full throttle on the core concepts. Real time processing is what you’d get if you were to run batch programs like MapReduce on the data instantly and continuously rather than waiting for a scheduled time/event at which the program will be run. This was exactly the earlier forms of techniques employed by the real time or should i say Pseudo-RealTime applications which achieved this by running batch programs more frequently to give the illusion of a realtime app. This is aptly called micro-batching as it was the program run multiple times on micro batches instead of gigabytes of data. This was done to reduce the latency and increase freshness or relevance of the produced data.
But as apps became more and more time sensitive, the need for the processing data instantaneously became lucrative and desirable and it lead rise of actual Real TIme frameworks like Flink and DataFlow. However, simply juxtaposing concepts of a Batch processing system to Real Time didn’t bode well as a newer paradigm brought with itself a newer set of challenges to deal with. So without further ado, let’s have a look at them !!
- Storage – The Distributed Commit Log
- Window.. of Opportunity
- Pipelined nature of workflow
- It’s ’bout Time !!
- Semantics.. Do it Right or Do it Twice
- Idempotency.. The One & Only
- 2 States.. of Processing
- Ordering
- Exception Handling .. The Show Must Go On !!
- Conclusion
Storage – The Distributed Commit Log.
Traditionally the input to nearly all the batch programs were files residing on top of the venerable HDFS processed by any of the numerous batch processing tools. In a streaming system, you technically don’t need a storage system, as the data/message is immediately processed and nothing is well, stored for future processing. You could however want the data stored for historic purposes or it could be used by some other tool to perform computations different than our streaming application. This can be achieved by writing the msg received on a file over HDFS. Albeit this is definitely not a requirement for our streaming system.
The problem here is that the above scenario I painted is an extremely ideal scenario as we are confident that the message received is processed immediately, hence the lack of a storage system. In the practical world, the components of a Big Data cluster are finicky systems which often slow down or fail altogether along with intermittent network issues. Assuming the incoming message stream is not persisted, we will lose all the messages if our application is not available to process the messages when they arrive into our system or if it can’t keep up with the incoming message rate due to sudden spikes.[ Cough** Flash Sales ** ] This is known as Back Pressure.
Hopefully my argument has made it clear why it’s imperative to store the streaming messages even if they are processed seemingly instantaneously. Having to process a stream of continuous events which would usually be unending, we need a storage system which can allow continuous reads and writes in a simultaneous and concurrent fashion. Writing the messages on files on top of HDFS won’t solve our purpose as we also want to process the messages simultaneously, which HDFS wont allow. Remember, the inputsplits of any hadoop job is defined at job creation and thus would only include the data blocks [or in our case, messages] present at the time at which the streaming job was started, and would ignore all the subsequent messages which were written to the files after the job was started. I delved into input splits in detail in my previous post, which can be read by clicking this link.
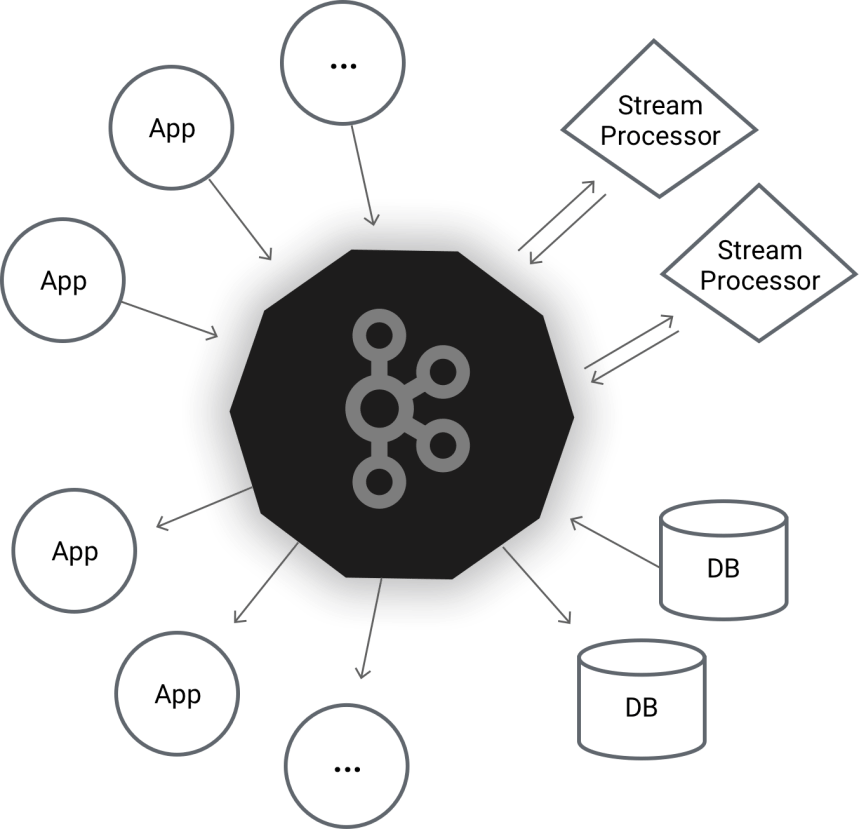
Kafka is a tool developed by LinkedIn which was designed to provide a persistent storage layer for all streaming needs. It works on the pub-sub model where producers produce messages into various Topics, and consumers read the messages by subscribing to those topics. Lets breakdown its official moniker, the Distributed Commit Log..
- Distributed
Just like most of the big data ecosystem components, kafka is distributed for exactly the same reasons.. Better performance due to horizontal scaling and fault tolerance. - Commit
The stream producer and stream consumer get and send acks when they produce or read a message respectively. This ensures that messages aren’t lost though they may be reprocessed again in case of failure recovery. More on this later when we discuss the semantics. - Log
Kafka in its core is a WAL or Write Ahead Log, where messages are written / appended to the end of file by the producer,
and are read sequentially by the consumers. Just as any file based system, random access is not possible.
Thus Kafka can be used as a distributed message queue with some level of persistence. This allows us to guarantee that all the messages are processed even if the consumers are unavailable momentarily as they can pickup messages from Kafka and continue from the point they left off before they failed. Having storage also helps to cope up with back pressure, as in case of a sudden influx of incoming messages, the messages are stored and can be read later by the consumers when the spike subsides. I won’t be getting into the operational details or concepts of Kafka as it can be found from their official documentation site.
Window.. of Opportunity
Probably one of the biggest changes in stream processing compared to batch processing is the concept of windows. Since the streaming app theoretically runs indefinitely, operations like reduce and aggregates can never be applied on the entire data, as the entire data is never there.. it’s simply being produced continuously. Instead we sample this incoming stream and apply our computations on a subset of the data. This process is known as windowing and the criteria on which we do the sampling decides the nature of window to be used.
Flink provides us with 3 Times of windows
- Count Window
Which collects a count of elements before computing the operation over them eg 4 elements.
- Time Window
Which collects elements over a certain time period eg 5 seconds
- Session window
The trickiest one to understand from the trio mentioned here, this window closes only after a set time of inactivity.
eg a session window of 10 minutes would close only after no element has been added into the window for 10 minutes from the last insert.
i.e. Each insert resets the timer of the window
Pipelined nature of workflow
The general workflow of a streaming engine like Spark or Flink would be
- Creating an Input or Source stream from a source like Kafka topic
- Processing
- Map operation over the stream which is most likely, converting the stream to a tuple of [key, value]
- Doing a KeyBy or MapToPair operation and creating a keyed stream to enable parallel processing. This is akin to performing a partitioning operation to send the data to the appropriate node for processing.
- Applying a window operation. This is the most important conceptual difference which I mentioned before. We do windowing to subset the infinite data stream into a finite set.
- Only after we have the windowed subset of elements, do we perform any of the operations like reduce or aggregate.
- Writing the output back to a Sink
The reason it’s called a pipeline, is because well, it resembles one !! You can see the various steps I mentioned in this pipeline. They start with the leftmost block being the source, followed by multiple transformation operations being performed on the stream and a sink at the end represented by the rightmost block.

It’s ’bout Time !!
We just saw how Time plays a vital part in the windowing operation where we can group elements based on the time. But the notion of time can be different from different perspectives. Most of the modern streaming applications support 2 notions of time.
- Event Time
Its the time when a particular message or event was generated. Think of it as a timestamp of the message. - Processing Time
This is the time when the stream processing system actually received and starts to process the input. This time is always greater than the event time accounting the delay due to inevitable latency between the producer writing the message and the consumer reading it factoring in delays due to serialization-deserialization overhead
Allow me to take up an extremely contrived example of any paid service which charges user on a daily basis. Whenever a user subscribes to any channel on DTH cable tv, at 12:00 am midnight, his subscription is renewed & he is charged for the service for the entire day. In such a payment model, most users unsubscribe a couple of minutes before midnight. Now imagine the user unsubscribes to the service at 11.55 pm. A cancellation request is generated and the cancellation service revokes the user’s services and writes this event into a Kafka Topic. Another service called billing service which is part of the same application reads this message & makes sure that the user is not charged for the next day. This sort of loose coupling is very common in a MicroServices based architecture.
Now for some reason, the cancellation service which is responsible for stopping the billing service slows down. It could be due to network issues or due to back pressure because a lot of users are cancelling their subscription a few moments before midnight causing a massive load spike. The cancellation service is unable to process some of the messages in time & by the time it has written the cancellation request on a Kafka Topic, the time is 12:01, falling into the next day
Though the billing service receives the cancellation request eventually, it got it late by a couple of minutes, which technically is the next day compared to when it was originally generated. This causes the billing system to charge the user for one more day even though he cancelled the subscription before midnight.
This problem happened because the billing service was considering the processing time of the cancellation request, which is the time the message was written into the kafka topic or the time it was processed by the billing service. So even though the user cancelled his service at 11.55, it was written to the topic at 12.01 due to lag or latency leading the billing service to consider this time & compute incorrect results. If it were to consider the event time which is 11.55, it will consider the time when the message was generated, ie time when the user unsubscribed from the service, leading to correct results.
Now to run the app according to Event-time, the messages need to have the event time info embedded either in the message header or in the body of the message itself, which can be later extracted by the flink job responsible for billing. This could be as simple as a transaction timestamp.
Semantics.. Do it Right or Do it Twice
Borrowing qualities like High availability and Failover Handling from their Batch processing brethren, all of the streaming frameworks restart their Executors / TaskManagers in case of any outages. In any of the scenario, a hardened & fault tolerant system can easily shrug off node failures or even outages of the cluster Master. Most of the advanced streaming app like Flink or Google DataFlow offer 3 types of guarantees when it comes to message processing after the system recovers from a failure.
- At least Once
- Exactly Once
- At most Once
At-Least-Once processing is when the system guarantees that the messages will be processed once under normal execution. and more than one times when recovering from failure. The point to note here is that the system might process some messages twice because it sends Kafka Commits only after the data is processed. So if the system crashes after picking a message from kafka but before processing and committing that record, it will pick that record back again when it restarts. Now this usually does not impact the business performance of the app, its just that unnecessary computations are done for the data which was already processed and perhaps even persisted but not committed.
But there are times when at least once just doesn’t cut it. For example there’s a huge difference between transferring 60,000 $ once vs transferring it twice. Or say placing order once and placing the same order twice. There are many more examples in sectors like the financial or e-commerce sector, and beyond where we require a high level of consistency. This can be resolved by making the operation idempotent, which we will look upon shortly in the next section.
Exactly-Once processing guarantees that it will process the message once regardless of any scenario of failure. But we all know there is no such thing as free lunch !! This setup is incredibly difficult to design, implement & test. Also there is the added overhead of maintaining the system state for both the stream processing system as well as the messaging system, which adds a tiny amount of delay or latency. Fortunately Kafka & Flink both support EaxctlyOnce but due to the complexities, this is best reserved for only for those sectors where it’s absolutely imperative for the data to be processed only once. I will save a detailed look at it for a future article.
At-most-Once processing is not worth discussing because I don’t think anyone uses this particular semantic in production environment because of the guarantees it provides, or lack thereof. It basically says that it won’t re-fetch or replay the messages again as a message once consumed is immediately marked as committed regardless of the success or the failure of the operation on the message. So this leads to data loss in case of recovering / restarting the machine after failure recovery which is unacceptable.
Idempotency.. The One & Only
We just saw that under At-least-once semantics, messages might be processed twice. This however leads to consistency issues. We briefly mentioned that the producers and consumers use Kafka as a storage layer. The Producer relies on acknowledgements to guarantee that the message has been written on Kafka.
The Consumers rely on offsets which are maintained by Kafka to track their current position in a message stream. This could be compared to a Database cursor which points to the current row, and would give the next row when advanced. Under default configurations Kafka uses auto-commit. When a consumer fetches messages, it will send a commit request for those messages only when it requests the next message batch. The interpretation is that the consumer is done processing the current batch when it requests the next batch, so Kafka internally moves the comittedOffset pointer to mark those records as committed and provides the consumer the next batch of messages to process.
To be honest there are multitude of things which can go wrong here.
Imagine i have a method like this where under ideal scenario, the consumer processes the records it gets from Kafka and inserts the result on ElasticSearch.
while(true) // practically most production grade streaming applications using kafka consumers run infinitely.
{
// poll the server and get the records to process
ConsumerRecords<Long, String> consumerRecords = consumer.poll(1000);
// process the records ..
ProcessedConsumerRecords output = consumerRecords.forEach(record -> doProcessing(record)) ;
// insert those processed records to another database .. say elasticsearch
insertRecordsIntoElasticsearch(output);
// commit the batch.
consumer.commit()
}
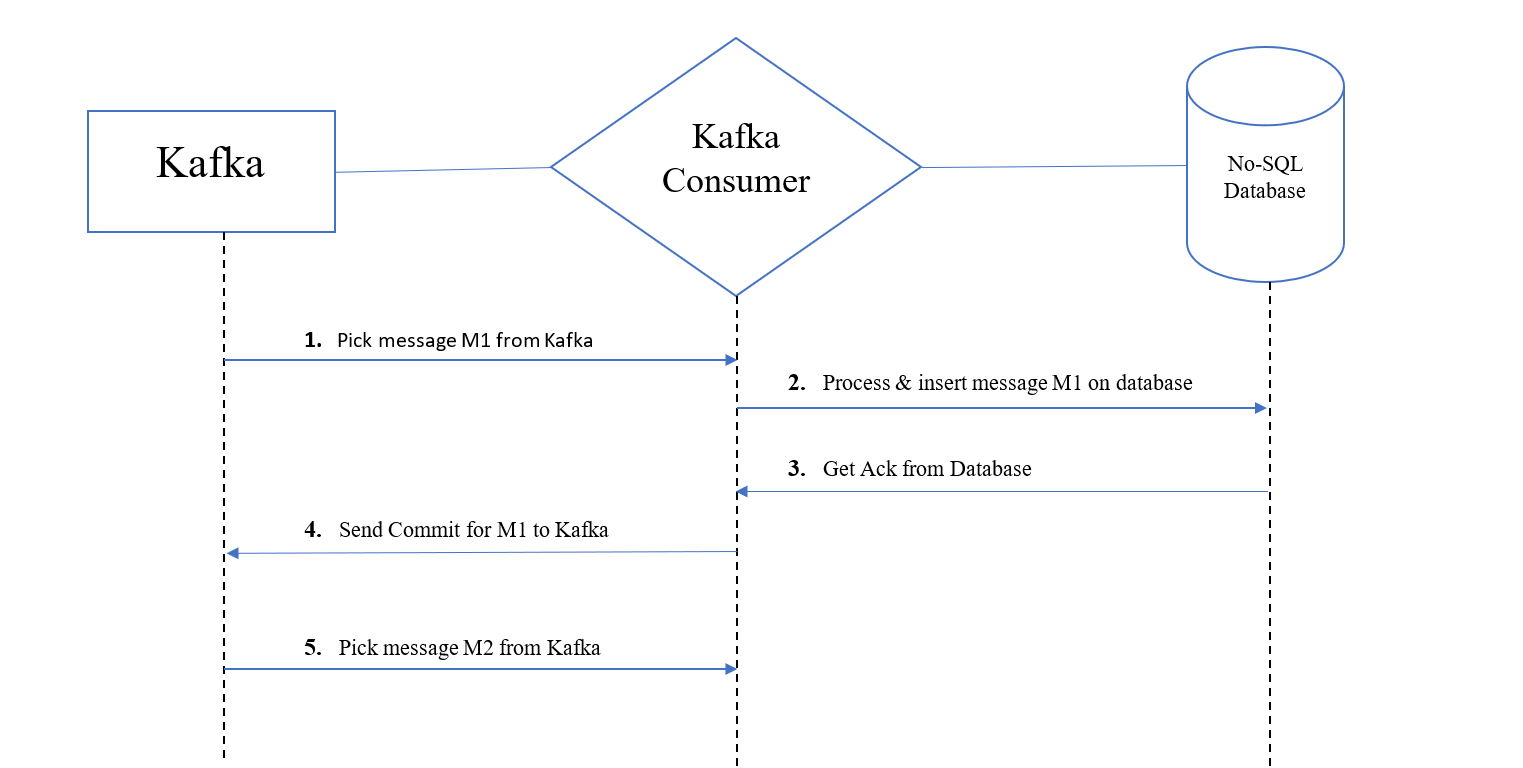
Idempotency means replaying or performing the action wont lead to change of result. The outcome of an idempotent operation would be the same if it is executed single or multiple times. This comes in handy when a kafka consumer running on a flink node is resurrected after a failure.
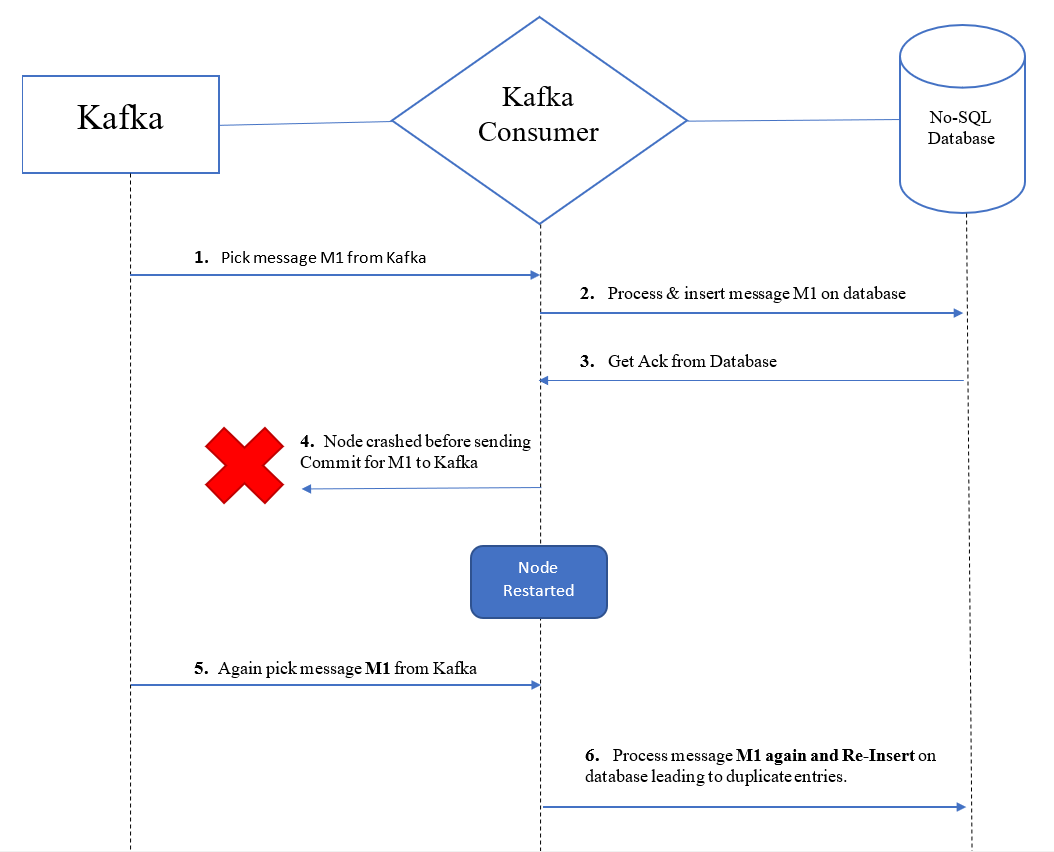
If you look closely at the last 2 operations, which is inserting records into ES and then updating the commit on Kafka, you will realize that they aren’t Atomic in nature. It’s possible that a consumer processed record R1 and inserted it into elasticsearch but crashed before it could commit it on kafka. When the consumer comes back online, [or is replaced by a new instance altogether] it has no idea that it has processed Record R1 because it wasn’t committed on Kafka and it will redo the processing and will RE-INSERT the record into the database again. Such operations are called Non-Idempotent operations.
As a rule-of-thumb, the moment an operation is split between 2 heterogenous systems, it’s next to impossible to make the operation Atomic. However it can be alleviated by making it idempotent by simply inserting the records with an ID. It is most likely that the data/message/document we insert will already have its own natural primary key [eg userId, phonenumber, email id]. This way, re-inserting them on RDBMS would not happen as they’ll violate the PK constraint [which can be handled] while on a NO-SQL database like ElasticSearch, the second subsequent entry will simply overwrite the preceding entry instead of creating a duplicate document on the database. This will only avoid duplicate records or entries present on the database as the message would end up getting processed twice, following Atleast-Once Semantics.
If you’re still unclear about non-idempotency, you can have a look at this advert where doing the same operation multiple times leads to unwanted results !! 🙂
2 States.. of Processing
In simple terms, State in RealTime systems refers to any information which is persisted in some manner to be used across two or more messages. This leads to 2 types of operations.
- Stateless Operations
- Stateful Operations
Stateless operations are those which don’t require any info about the previous messages. They simply operate on one message at a time, do their computations, send the output downstream to the succeeding component of the pipeline and then pick up the next message. Example of this would be an operation which parses a JSON to an object and sends it to the next operator. The parsing activity doesn’t rely on the previous JSON, and all the info needed by this operator for parsing is contained in one message.
Stateful operations save information between messages to do their operation. Eg keeping a count of number of inserts done on a database. The reason its stateful is because it keeps information about the messages which have come prior, & that information is count.
We saw at the beginning of the article how and why streams of messages are windowed together ; & applying this notion to concepts of Windowing, we can say that Stateful operations are those which keep track of information about messages across Windows.
Flink internally uses its stateful operators and variables to save information and uses it to recover in case of failures to achieve Exactly-Once-Semantics.
Ordering
Ordering any concurrent operation in a distributed environment is an extremely difficult thing to do. This is precisely the reason why most of the multithreaded algorithms take order out of the requirements due to its unpredictability. A lot of efforts programmatically will have to be poured into developing, designing & maintaining such a system. So our first goal here would be to eliminate the need of ordering entirely.
However, in financial and banking domains, if we have an empty bank account, there’s a HUGE difference between depositing 1000$ and then sending 500$ vs trying to send 500$ from an empty account and then adding 1000$. Kafka fortunately has the provision for providing ordering guarantees. Having a strict ordering implies the consumers will receive the messages in the same order in which the producers produce.
Well, atleast sort of.
In Kafka,
- the Topics onto which messages are written have the data distributed across multiple chunks called partitions.
- Kafka guarantees the ordering of messages inside a partition only. Messages in a topic spread across multiple partitions will not be ordered. Total Order is not provided.
So to enable ordering, we can do one of 3 things listed below
- Keep the number of partitions to 1
This would work because kafka guarantees order in a single partition and if the topic only comprises one one partition, the entire topic is ordered as well.
This however effectively turns the parallelism to one & heavily bottlenecks the topic’s throughput to anyone using it [producing or consuming].
Thus this is not a practical approach. - Producer produces messages with a key and value
By using a custom message partitioner, we can guarantee that all messages from one key will be written to a single partition which will guarantee its ordering.
This can be used in cases where we want the order to be maintained , but different message keys can be processed in parallel without any correlation between them.
Eg, Bank transactions of one user will be ordered in one partition while that of another user which is completely unrelated would be ordered in another partition.
This enables parallel processing without compromising on the ordering and this is one of the more practical approaches. - Keep number of partitions and number of consumers same.
In Kafka, consumers consuming a topic can be increased by adding more consumers to the same ConsumerGroup.
They will share the reading responsibility by consuming messages from multiple partitions, increasing performance by virtue of parallelism.
Keeping partitions and consumers same guarantees us that the messages read by the consumers will be in ascending order though not sequentially ordered.
When the consumer reads records, we can guarantee that the current record will always be greater than the previous record.
This can be used in interesting ways to achieve Exactly-Once Semantics, which we will have a look at towards the end of the article.
There is one more configuration which needs to be tackled. max.in.flight.requests.per.connectionneeds to be set to 1. Quoting the definition from the actual kafka documentation ,
Setting a value greater than zero will cause the client to resend any record whose send fails with a potentially transient error. Note that this retry is no different than if the client resent the record upon receiving the error. Allowing retries without setting
max.in.flight.requests.per.connectionto 1 will potentially change the ordering of records because if two batches are sent to a single partition, and the first fails and is retried but the second succeeds, then the records in the second batch may appear first.
This means, when we have message retries enabled [which is, nearly always] we might have a scenario where the producer sent 2 message batches one after the other without waiting for an acknowledgement for batch one to finish. If batch one fails but batch two succeeds, the producer will after some time, retry batch one which will succeed now thus reversing the order of messages written on the topic [Batch 2 followed by 1].
Exception Handling .. The Show Must Go On !!
In any distributed application be it batch or streaming, most of the functionality provided will be via the code encapsulated in various MapFunctions, ProcessFunctions [Reduce, Join, Aggregations], Filters etc. The common feature in all these is that the code is run on a cluster in a separate JVM & these methods are given the input elements and they in turn do the computation on each message.
But what if a particular message leads to an exception scenario ? Consider the example of JSON parsing. There is an unending stream of records to process and the operator’s map method takes in a String as input and emits the parsed JSON object. Now if there is a parse exception in one of the records in the stream, it will lead to a JsonParseException which if not handled, will thwart the streaming job because under the presence of a restart strategy, its highly possible that this job will be retried with the same message that caused the error which will again lead to an exception and our job crashing and retried which will fail again. As this keeps happening, the number of times the framework retries the job keeps incrementing and after a set number the framework will kill our job and the remaining won’t be processed.
The ideal scenario is here is don’t throw exceptions & handle the exception on a per message level, log it perhaps to a Kafka topic dedicated to erroneous records & proceed to the next message. The pipeline must not stop !!
Conclusion
Inspite of all the things I just covered, what we have seen here is just scratching the surface. The world of streaming is constantly evolving & I firmly believe we have lots more to come. I will definitely be writing much more about streaming in the coming future. Hopefully this article will help those who are undergoing the paradigm shift like me 🙂

4 responses to “Undergoing the Paradigm Shift – Batch Processing to RealTime Streaming”
Thank you for this information. You covered great depth with it.
LikeLike
Thanks Ajay !! Much Appreciated 🙂
LikeLike
[…] my previous article, I wrote my thoughts on the Paradigm Shift I underwent adapting to the idiosyncrasies of real time systems when compared to batch […]
LikeLike
[…] Restart strategy which I wish I knew sooner. Also if you are new to stream system development, checkout my previous article where i wrote about the change of mindset required to move from batch to stream development. With […]
LikeLike