Having worked with Kafka for almost a year and half , I wanted to share my thoughts on Kafka’s consistency guarantees and how to achieve them. I will be skipping over the details of basic configurations and suggestions like having multiple partitions & setting the replication factor to be more than one because those are extremely well known common configurations and its hard to get those wrong. Needless to say, Kafka should be running in a multi broker mode to avail consistency.
Consistency does NOT mean Zero Downtime / High availability.
This is one of the naive assumptions I had when I started reading about the internals of Kafka and guarantees it provides. Kafka is a messaging system which has the notion of Producers & Consumers. The part which makes Kafka different than a typical message bus / queue is that there can be multiple consumers [belonging to different groups] reading the same message which was produced once. [Messages aren’t removed when read]. As Kafka is distributed, the data is replicated and with it comes a chance that the replicas are not in sync with each other. By making the system consistent, we guarantee that no matter what happens to the state of the cluster, the data read by all the consumers of particular topic will always be the same regardless of system failures in the cluster.
This state of consistency can include a downtime too !! Zero data being produced by producers or read by consumers is also counted as a consistent behavior 😛 which is what happens when we chose a CP system. Here we forego availability for extreme consistency across the cluster. The perfect scenario for such a setup would be the Banking & Financial sectors where these organizations cannot afford any sort of inconsistency in their data & would always chose a downtime of a service like a payment gateway instead of financial miscalculations i.e. Consistency and Partitioning are chosen over Availability.
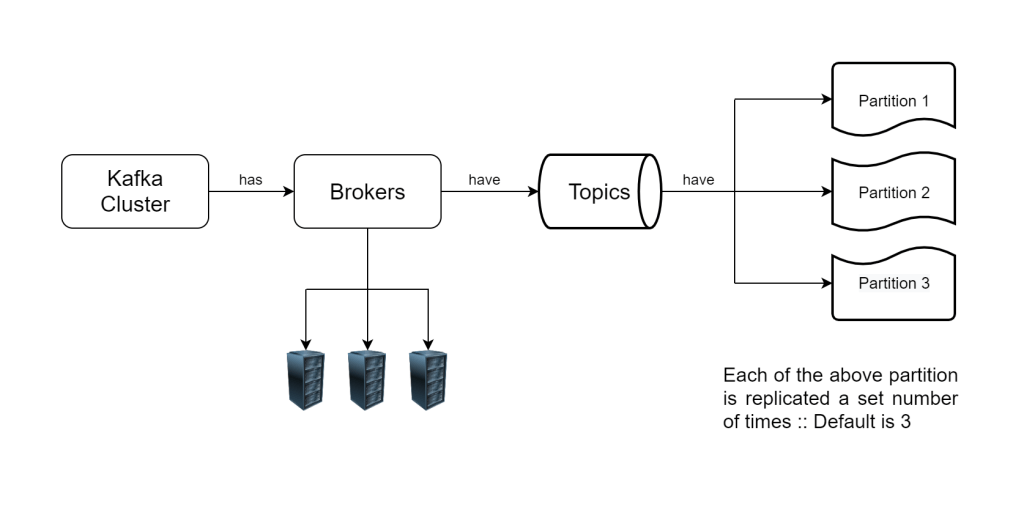
Kafka Topic Overview

Each Kafka topic is a distributed abstraction which consists of various partitions. Each partition has one leader partition which is responsible for handling the read and write requests. Its complemented by a number of follower partitions which replicate the leader by reading and persisting all its messages to provide fault tolerance for the leader. The follower partitions can either be In-Sync with the leader if they have caught up to and replicated the latest messages produced in the leader. Conversely they can be Out-of-Sync if they are yet to read and replicate the latest messages in the leader partition. Partitions may frequently transition between in-sync and out-of-sync states if there is network slowdown between the leader & follower partitions. We can infer that, In-sync replicas offer the most consistent view of the Kafka partitions , and hence the topic.
Configurations
unclean.leader.election.enable– falseUnclean Leader Election [Topic level or Cluster Wide configuration ]
This can be configured on a Cluster level so that it affects all the topics in the cluster, or the more common approach is to configure it for each topic so that its upto the topic creator to decide the consistency level. This setting ensures that when the leader partition of a topic goes offline, the next partition which will be elected as a leader needs to have been insync with the leader. If no such partitions exist, then the cluster would not accept any Produce or Consume requests which it gets and hence the topic becomes unavailable (Consistency over availability). For a consistent cluster, we should set the value to false so that the cluster will stop processing requests instead of electing an Out-Of-Sync follower partition as a leader which may not have the latest messages from the leader causing data inconsistency.min.insync.replicas– 2 or moreMinimum In Sync Replicas [Producer or Topic level configuration]
This configuration forces the producer to only produce messages as long as the said number of In-Sync replicas are present for the partition its writing data to. This ensures that in the event of loss of the leader partition, we will always a candidate for leader election as the previous configuration alters the cluster behavior to only elect those followers who were in sync with the leader, as the next leader when the original leader goes offline. Setting a value of 2 or more is imperative here because if set to 1, then the leader is counted in ISR and acks all would just count the leader if the followers are out of sync. And in such a scenario, the failure of leader would leave the cluster with no followers eligible for leader election and lost data because the producer got acks for the messages which were only persisted to the leader partition which went offline.acks– allWrite Acknowledgements [Producer configuration]
Setting the acks to all makes sure that the producer waits for its message to be acknowledged by all the In-Sync replicas before moving over and producing the next message. And since our min.insync.replicas is more than 2, we can be sure that our message has been acknowledged by atleast more than partitions, making the system more resilient as this helps us avoid the scenario where the leader fails after acknowledging our message but before any of the follower partitions could replicate it.
