
With the introduction of YARN in Hadoop2, the resource scheduling engine got a massive overhaul. Gone are the days of the older slot based system for MapReduce framework, which was removed and replaced with a container based system. Intended to be more flexible than its predecessor, this new system is far more dynamic and allows for a achieving a higher cluster utilization. But with great power, comes great .. difficulty in understanding the intricacies of the new system. Which is why in this article, I’ll be shedding some light on this topic.
Concurrency vs parallelism
Before I address the elephant in the room (pun intended !!) let me get a couple of things out of the way as understanding this section is paramount to understanding the rest of the article. I’m talking about the difference between concurrency and parallelism. Take up any modern operating system, and you’re bound to find these 2 concepts playing a vital role.
Concurrency is the ability of a computer to start multiple programs (processes) and execute them in an interleaved fashion where in the CPU is shared across multiple programs One at a time. In simpler terms, the OS starts a program (P1) and before it finishes, it pauses P1 and starts up another program(P2) and after a while, pauses P2 and goes back to P1. It does this till both P1 & P2 are have fully finished their execution. This usually happens on a Single core machine.
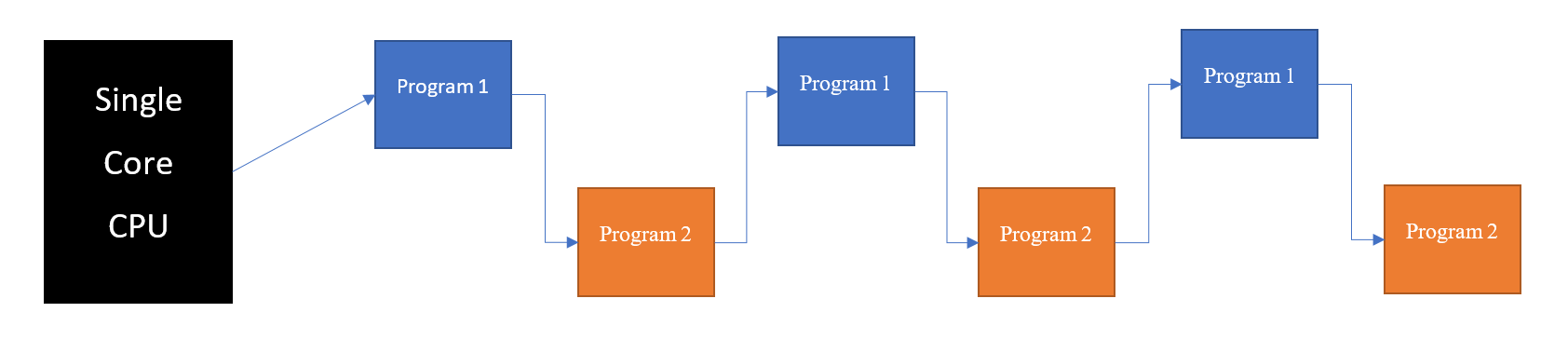
Parallelism is when the system can execute multiple programs Literally at the same time. This happens in a multi core CPU where the OS starts and executes (ideally) one program per core.

It’s clear that concurrency just gives the impression of tasks being executed simultaneously but will take the same time as if they were run sequentially. Parallelism on the other hand, will actually lead to time reduction. Hence, in this article, parallelism is the only focus.
Hadoop Job scheduling and the factors involved
In MapReduce, each Request which the client submits, known as a Job, is divided into multiple tasks (map_tasks and reduce_tasks) and these tasks form the execution units for that Job. You can check out my previous article Small files.. Big problem – where I wrote about how the framework generates these tasks in detail and an underlying problem with the default behavior. These tasks are executed in parallel by the framework on the various machines on the cluster taking into account data locality. It is this parallelism which is responsible for Hadoop’s performance.
For the rest of the article, I’m gonna assume that the Hadoop cluster has the 12 virtualCores (6 physical cores with hyperthreading) and 48 gigs of ram as its configuration (taking into account all the nodes part of the cluster). Now let’s have a look at how the old and new versions of Hadoop handle the above hardware.
Hadoop 1 – The Slot machine
Hadoop1 has a very easy to understand yet somewhat rigid resource management system where
- the Cluster admin would configure the number of Map_slots and Reduce_slots available
- Each of the Map_task and Reduce_tasks would occupy one slot during its execution cycle.
- The slots are not interchangeable – Map_task will only run on free Map_slots and similarly Reduce_tasks would only run on free Reduce_slots.

Lets assume hadoop cluster is configured as shown below, which is line with the 3:2 mapper vs reducer ratio as mappers are the ones dealing with the entire bulk of the data.
- 3 Map slots — Each map slot having 10 gigs of ram and 2 virtualCores.
- 2 Reduce slots — Each reduce slot having 6 gigs of ram and 2 virtualCores.
- The remainder of the resources are left out for Linux & the various cluster management services.
The slots themselves are fixed and a restart of the nodes is needed to update the value. The amount of parallel tasks running at any given time is equal to and can never exceed the slots available in this cluster. This creates 2 problems.
Problem 1
If we run a Sqoop job which is map_only by nature, only the map_slots will be used and the rest of the hardware reserved for the reducers will be idle. Now I know that a cluster will be handing more than one jobs submitted at a time and so the reduce_slots for most part won’t be idle. But due to the rigidity of the slot system, map jobs can’t be scheduled on reduce slots even if they are idle.
Problem 2
If there is a job which has a small tasks with each needing less ram than what our slot is configured to offer, even though the cluster can schedule and run more than one task, but due to the nature of the slot system.. 2 small jobs can’t be run on a large slot and they will be run sequentially. This a far more common occurring problem as the slots aren’t elastic in nature and having the right config is essentially a tradeoff between.
- Having a small number of large slots, which affects parallelism as the small tasks could have been executed in parallel.
- Having lots of small slots, which has its own share of problems as the tasks which need more ram will cause out-of-memory exception or will timeout after waiting too long for a larger slot (which is not available)
The only solution (workaround) to the above problem is to update the slots and restart the cluster depending on the type of job. Obviously which can’t be done in a regular basis.
Hadoop 2 With YARN
Hadoop2 introduces Yet Another Resource Negotiator abbreviated as Y.A.R.N which brings along with it a new Container based resource allocation system. Lets have an indepth look in the working and see how it solves the the limitations present in Hadoop1.
In hadoop2 with YARN, the cluster admin simply configures the resources for each node which can be offered in terms of the virtualCores and Ram offered on a per node basis. When the cluster starts up, special daemons in each nodes called NodeManagers report their capacity to the ResourceManager, which is the master of the YARN system. The tasks state their memory and ram requirements in their configuration for their map and reduce tasks and accordingly the YARN scheduler tries to allocate a container with the specified resources on a free node in the cluster, taking into account Data Locality.
Taking the same hardware config of the cluster as mentioned in the previous example, all the admin has to do is configure the memory and vCore for each node such that the total values across the cluster represent
- yarn.nodemanager.resource.cpu-vcores to 12
- yarn.nodemanager.resource.memory-mb to 42gb
When the nodes startup and connect with YARN, they register their memory and vCore values and post that, the resource scheduler in YARN handles the rest. This makes the resource allocation highly elastic as depending on the job requirements, the YARN decides whether the cluster has the hardware required to execute the tasks in parallel or do them sequentially.
Now, the MapReduce dev/programmer has to specify how much ram and vCore his program needs for each of the map and reduce tasks by setting the following parameters in the jobConfiguration
- memory –> mapreduce.map.memory.mb and mapreduce.reduce.memory.mb and
- vcores –> mapreduce.map.cpu.vcores and mapreduce.reduce.cpu.vcores
Solution to Problem 1 (Map only jobs)
Map only jobs like Sqoop can benefit from a higher cluster utilization as all the mapper does is requests its memory and vcore requirement. Accordingly containers are allocated and if the cluster has no other jobs running, nearly all the resources in the form of containers are given and the jobs are executed in parallel.
Solution to Problem 2 (Static Slots vs Dynamic Containers)
Being highly flexible, resources allocated to the containers is decided on runtime based on the free resources available in the cluster and thus handling of both types of jobs is handled effectively without the need to ever restart the cluster.
- Jobs with larger memory requirements are allocated containers with a bigger resources and are sequentially executed if they can’t be run in parallel.
- Smaller jobs (needing less resources) are executed in parallel as there is no static sized slots.
A couple of things to note
Below we can see the execution of a simple Mapreduce job on YARN. I want to touch upon a few observations.
- As we can see, 12 vcores & 40 gigs of ram was allocated for the following job
- All the 4 mappers were executed in parallel, which can be verified by their start times
- Reducer is in a scheduled state as we have run out of resources and will be started once YARN gets free resources, in our example , its once any of the mappers finish.
The perplexing thing to note here is that even though only 4 mappers were spawned, and the reducer is not being currently executed (its in scheduled state), the Running containers shows 5. This is due to the fact that a small container is allocated for the ApplicationMaster daemon which keeps track of the progress of the submitted job. So the number of running containers will always be one more than the actual ones doing the MR job.



